Another week came to pass and I have managed to do some work on my project. Unfortunately I didn’t work on it as much as I would like to, but nonetheless, I have finished writing the parser for timetables and routes data. And that counts as a success.
Writing a parser for each section was one of the most boring things I have ever done, it is really not fun, trust me. But it’s done and I must say, that I am pretty happy with the result. It has some rough points here and there, some things I could have made a bit better, but it’s ok. Maybe in the future, I’ll refactor this code a bit. For now, it stays, it works! At least that’s what tests show me. All are green 🙂
In addition to section parser for each separate section, I have also created a RootSectionParser. It has the same construction as all other sections, but its job is to parse the whole input data file and launch all other section parsers when needed. It is the glue that connects together all this parsing logic and produces a single object containing all the data in aggregated form.
Here is the structure of the resulting objects that represents all the data that is available:
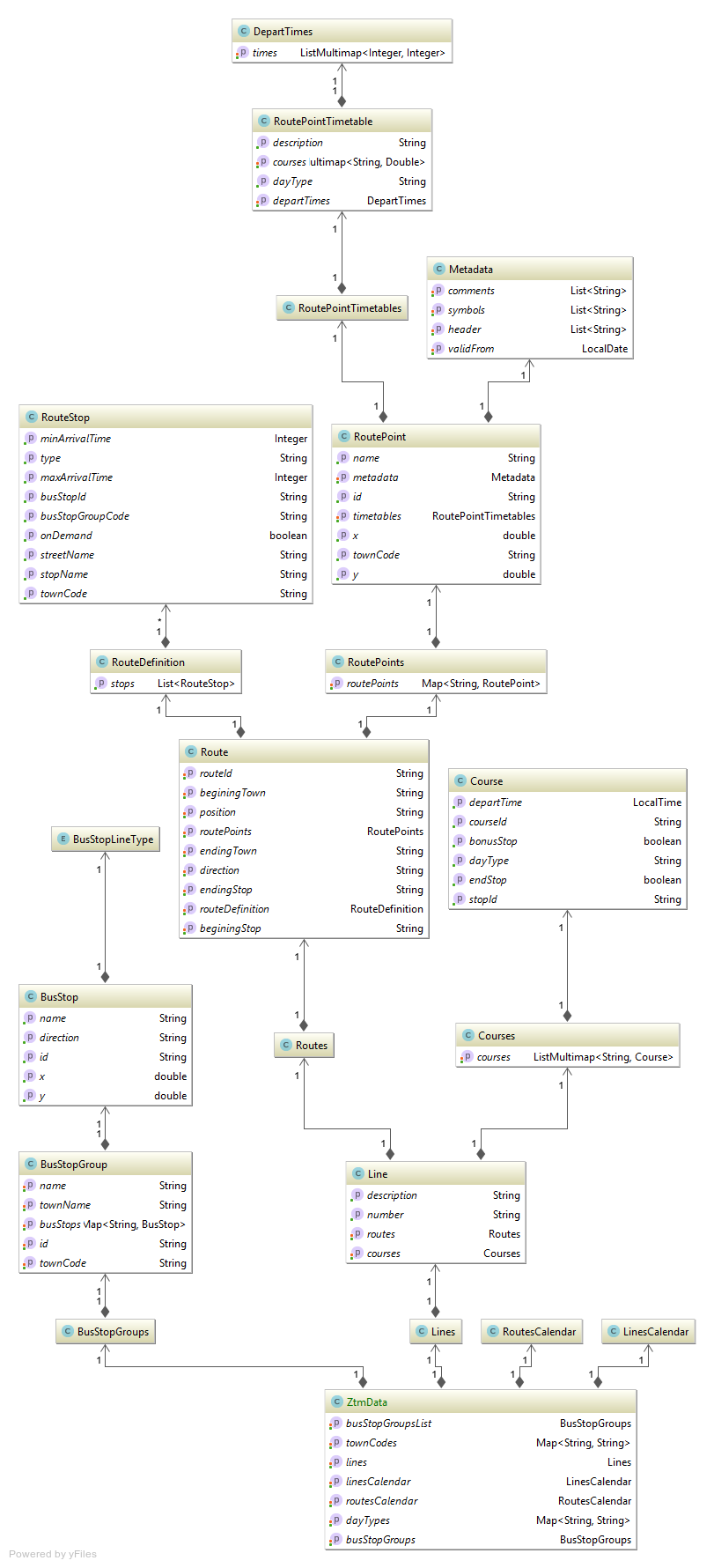
As you can see, it is a bit complicated and also has some redundancy here and there. But at this point, I wanted to read the file into memory somehow and think later about how to prepare all this data for use in my project.
The next thing that I have to do is to analyze all this, decide what data I need and design the database. That for sure will be fun and challenging. I still have some learning about Neo4j to do, I have the basics worked out, but the whole design is still a bit foggy.
In the next post, I plan to write a bit more about what Neo4j is and how it differs from traditional relational databases, so if you are interested, stay tuned 🙂
Also published on Medium.