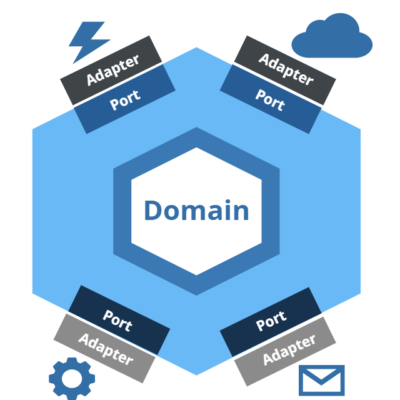
Last time I wrote about the general design of the Ports and Adapters architecture. I have also described how I plan to use this approach in the Commutee app with the focus on the primary ports, that is the entry points to the application. This time I’ll focus on the secondary ports, the ports that domain requires.
For now, the only part that Commutee needs is the database. Well, it needs some kind of business logic because it does not have any yet, but let’s assume that we are in the design phase.
There are few use cases for the database:
- creating/updating bus stops and their connections
- finding a connection
- finding a route of a bus line
- finding a timetable of a specific bus line at the certain bus stop
Here I am thinking about two possible approaches. First one is pretty simple. Create one interface, called DataStoreSercvice, and add to it all the methods that are needed for the above use cases. It seems ok, well it would work, I would have the needed separation from the domain that I want to achieve. But I don’t like it really. I would have one interface with probably more than 10 operations, which would then translate to a pretty big implementation class. But that is a secondary problem. The more important one is that I am not yet sure that I would use only one database. All the connection data will end up in Neo4j, that I am sure of. The thing that doesn’t feel like a good solution for me is storing all the timetables, the departure times etc. in the graph database. It’s not the type of data that should end up in a graph. I don’t know yet where it should end up, but I know that is should be somewhere else. Having all these operations in a single bag would make it really hard to switch the database for the timetables part.
Let’s split it up.
In one bag, I will store all the connections functionality, let’s call it ConnectionsStoreService. In the other one, I will have all the timetables querying functionality, let’s cal it TimetablesStoreService. I won’t be writing what exact methods will be in each of them because I don’t know yet, I have to think about it a bit more. But separation like this gives me a lot of flexibility. I can try to use one database that implements both these interfaces, I can use two implementations, even if they connect to the same database, I can use completely different databases or even I can use some remote service that will implement one of these interfaces. And this is great about this kind of architecture, that domain is completely independent of the specific implementation. I can easily switch data store implementations without the need to change anything in my domain.
How to implement this?
It sounds all great and simple, but is it really that simple? First I have to structure my packages in a way that would let me separate all these parts.

As you see, domain is completely separated from adapter parts like REST and database. Also, timetables parser is considered here as an outside part, an adapter to the loader port. That way I am able to cut it out into a separate application if I would need to in the future. All the DTOs are next to their port interfaces in the in and out packages. That way, all the classes are segregated by their context and not by their type of object. Domain business logic will end up in the service package.
Separation like that adds a bit of complexity but it has few important advantages. I’ve already mentioned the first one, grouping of classes by context instead of type. That means that for example, all the classes required for the REST endpoint, that are not the part of core domain are placed under one package. This makes it easier for a developer to work on that part because he doesn’t have to jump from one place to another.
The second advantage is that this approach strongly discourages usage of objects from different layers in other layers. What I mean is that our database entity classes should not be used outside of the database communication code, it should not be used in business logic because this creates a very strong dependency of business logic on the database. The same can be said about REST endpoint DTOs that are serialized into or from JSON. These should be translated to domain object before invoking business logic.
Also published on Medium.