Some time ago I wrote about Ports and Adapters architecture, where domain logic is completely separated from infrastructure logic, like database connection, rest controllers, clients etc. It’s is great if you have external dependencies and you want to just test your domain logic without the need for low-level mocking of dependencies. But what if you have a single codebase, a monolith app? Is it useful here? The TL;DR answer is… YES. Here’s why.
The standard approach
The standard way of writing software in a layered manner is to use an interface for some kind of service, with the defined API of this service and behind the scenes, have some class that implements it. That way, we have an exposed, public API that we can later use if dependent services and other components. We can use this internally for defining internal and external module dependencies. So, for example, we have a Service A from Module A, which depends on Service B from Module B. But this dependency is defined on the interface of Service B. The concrete implementation is not mentioned here explicitly. Service A doesn’t care what implementation of the interface is it connected to. It looks like this:

The above approach is ok, it is not bad. But the problem starts to appear when we have more classes that depend on the Service B, for example, some internal components of Module B.
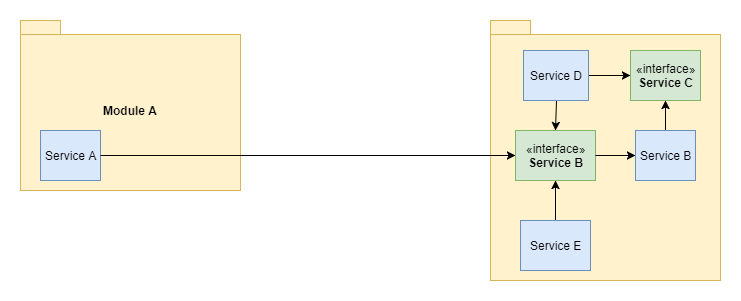
In a situation like that, everything works, Service A still doesn’t care about the implementation of Service B. But what if we would like to refactor Module B internal dependencies, make some changes to the internal communication between services? Well, we can’t do much, because the whole internal structure of Module B is now rigid. Service B can’t be changed, we can’t refactor whole Module B because we could break dependencies, we can’t do this without also changing Service A so that it would be compatible with our changes. And this is not a good thing. And the above example shows only 2 modules, think about what happens in a real world application where you can have many more modules.
Make an API
One solution to the above problem is using Ports and Adapters. We isolate our domain logic (dashed red rectangle) from our external API. We create an interface with modules public API and the implementation of said interface. Now Service A depends only on Module B API. We can change the whole internal structure of Module B, we can do whatever we wish, except changing the Module B API interface. That is the only rigid and exposed part.
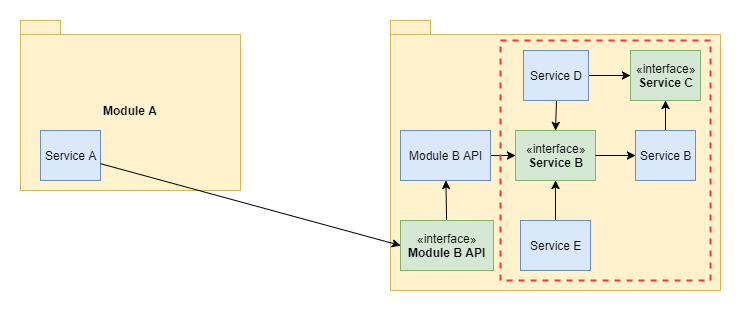
But that is only a half of the way to make it really flexible. Module A also needs some buffer zone. What if we would like to use some completely different module? But we don’t want to change the domain logic, it is already stable, it has good tests coverage and is working well. We just need some other kind of data source. For example, we have used a database connection, but now we want to switch to some REST Service to get the data? The data is the same, it is just obtained in a different manner.
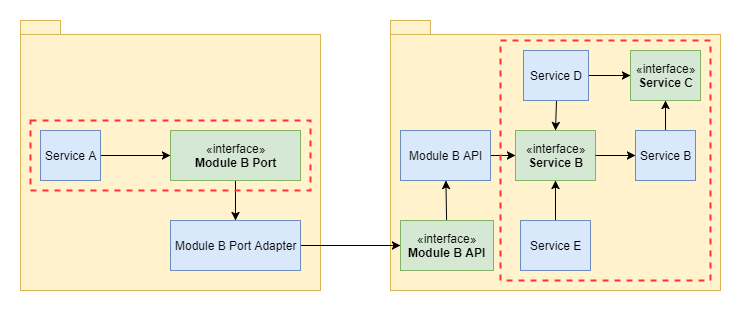
To do this, we should define a Port that provides the data we need to our service. We just define an interface that offers the functionality we need, that it has methods with certain arguments and returns data in a certain format. That is all that we care from the Service A point of view. With dependencies defined in such way, we can easily test the domain logic, we can easily mock this interface, without the need of mocking whole Module B API, which may have many more methods, and return much more data than we care for. For example, it can return Users list with the whole user information like birth date, shipping address, contact information etc. when we only need a list of user logins. Polluting Service A with all this information that has to be filtered creates an unnecessary noise, make code much more complicated to understand and much more complicated to test because now we have to mock whole User data. If we only use and API defined in port, which just returns a List of Strings, all that we have to mock is a List of Strings that resemble user logins.
All our data obtaining and data transforming logic is now enclosed in Module B Port Adapter, which connects to some other Module to get the data. We can have multiple implementations like that, which we can use for different scenarios, whenever we need to switch to some other data source. Everything is clean and nicely separated.
What’s next?
Writing a monolith in such manner also gives us some future flexibility. As I said earlier, we can switch the module that we depend on to some other one, with no changes in the domain logic. We can also create some Fake implementation that can be used for testing instead of creating mock. Fake implementation can have full functionality but simplified. For example, if our module has some CRUD operations that in the real world are performed in some kind of database, we can provide an implementation that performs all these operations in the memory, on a HashMap for example, where we just store object with an Id as a map key. It is fast and simple.
And there is one, more great advantage. We can break our monolith into microservices, one module at a time. We just take the whole module, for example, Module B, we extract it to the separate application, instead of Module B API we create Rest Controllers or some other kind of endpoints and we deploy this somewhere. Then, we create a new Module B Port, create an implementation that connects to the module B through Rest, and it’s done. We have just extracted one module from our monolith with minimal changes.
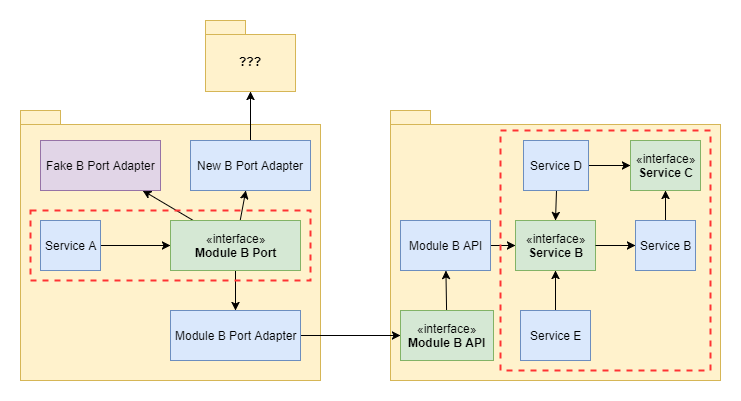
Of course, migrating to microservices is much more complicated, but I think that this is one of the hardest steps, isolating the module logic without breaking the application.
Sample project
On my GitHub, you can find a repository with a sample application that is created using the above approach.
There are few important things. First, the way I structure the packages tree. I keep the domain and infrastructure separated. The domain is all your business logic, database model, your services, DTOs, exception, port interfaces and everything that is important in terms of your domain. Some may argue, that database model should be excluded from domain, as it is a part of the infrastructure. In general, I agree with this, but often if we are not using some kind of legacy database, where we have existing structures, we can model it in a way that is useful for us. So in a situation like that, where our business logic defines database model, we can keep this model in the domain part of the application.
In the infrastructure, you keep all other stuff that is required for your application to talk to the outside world, to configure itself, to publish an API etc. The best approach, in my opinion, is to have a different set of DTOs for different parts of your infrastructure. So for example, if you publish a REST API, you should define DTO designed for this API, if you also publish some SOAP API, then create another set of DTOs. These DTOs should also be separate from your domain DTOs, so that you won’t create a rigid dependency. I know, that for some it may look like an overkill, but it saves you a lot of trouble in the future and encourages you to create the DTOs that will have only the necessary fields, that way you have to write less 😉
The adapters, the bridge between one domain and the other, I prefer to instantiate through a Configuration bean so that if I would have different Adapters available, I would easily be able to switch them. Also configuration class like this gives a good overview of modules that are used by this module.
Also published on Medium.